
Quem já tentou fazer programação com blocos sabe que chega um ponto em que a produtividade deixa a desejar. Por isso é interessante fazer a programação dos kits Lego Mindstorm usando Python.
Nesse sentido a documentação oficial para fazer isso é bem ampla mas me pareceu possuir algumas lacunas para quem está começando. Foi pensando nisso que eu escrevi esse post.

Hardware utilizado:
- 1kit Lego Mindstorm EV3
- 1 cabo USB
- 1 notebook
- 1 cartão microSD de 2GB
Instalando o Python no cartão SD
A documentação oficial diz que o cartão SD deveria ser de, no mínimo, 4GB mas eu utilizei – com sucesso – um cartão de 2GB.
O primeiro passo é baixar a imagem que contém o software necessário para rodar Python no Lego. Essa imagem na verdade é um Linux modificado. No momento da escrita desse texto o link para download é https://education.lego.com/en-us/support/mindstorms-ev3/python-for-ev3.
Tentei usar o software Balena Etcher para gravar a imagem porém ao final o programa mostrava um erro mas não dava mais detalhes do motivo do erro. Talvez seja pelo tamanho do cartão SD. Não fiz um teste com um cartão com maior capacidade.
Para contornar esse erro do Etcher fiz a gravação com o comando dd do Linux. Veja abaixo a linha de comando completa:
cat ev3-micropython-v2.0.0-sd-card-image.img | sudo dd bs=4M of=/dev/sda
Como esse não é um tutorial de Linux, não vou entrar em detalhes, mas resumidamente o comando acima pega o arquivo da imagem e faz a cópia no dispositivo /dev/sda. No meu caso esse era o cartão SD. Confira muito bem se esse é o seu caso pois se você usa um disco rídigo então /dev/sda pode ser um pendrive ou até mesmo o seu disco rígido dependendo dos dispositivos de armazenamento conectados e o comando dd apaga todo o conteúdo anterior do dispositivo. Mesmo se /dev/sda for o seu cartão note que você perderá arquivos que estiverem nele.
Após o comando encerrar, desmonte a unidade e retire o cartão do computador.
Agora insira o cartão no computador Lego e ligue o mesmo. Se der tudo certo após uns 10-15 segundos deverão “correr” letras pequenas na tela do computador Lego.
O vídeo abaixo mostra essa parte do processo. Note que essa inicialização pode demorar. No meu caso a inicialização em si demorou 45 segundos pois a imagem Linux que está no cartão precisa fazer a detecção do hardware entre outras verificações.
Programando com Python
Se a inicialização ocorreu conforme esperado então agora começa a parte mais divertida.
Documentei os passos com as imagens abaixo.
1º Instale a extensão “EV3 Micropython” no Visual Code.
2º Depois que a extensão tiver sido instalada aparece uma opção nova do EV3 Micropython no menu lateral do Visual Code

3º Clicando nessa opção abre um menu um pouco mais pra direita com opções de “Criar um projeto novo”, “Explorar projetos de exemplo” ou “Abrir o guia do usuário”.

4º Clicando em explorar projetos de exemplo vários subtópicos, cada um com vários exemplos aparece na coluna da direita.

5º Depois de clicar em um dos exemplos o menu lateral vai mudar mostrando alguns arquivos. O que nos interessa, por padrão, tem o nome de main.py
Esse é o arquivo do seu exemplo/programa.

6º Clicando no arquivo main.py na coluna principal o código vai ficar disponível para você editar.

7º Uma vez que você criou o seu programa (ou carregou um dos exemplos). É hora de passar o código para o Lego. Conecte o cabo USB no computador e no kit LEGO e verifique a opção “EV3DEV Device Browser” na parte inferior do menu lateral.

8º Fiz alguns testes usando o ambiente Windows e o ambiente Linux (Pop OS! 20.04) e enquanto a detecção ocorreu automaticamente no Windows, no Linux foi necessário desconectar e conectar algumas vezes o cabo USB e clicar em “Click here to connect to a device”. Como eu usei dois notebooks diferentes não sei se o problema é do notebook ou do sistema operacional.
No Linux depois de clicar na opção de conectar, foi preciso escolher o dispositivo em uma menu no centro.
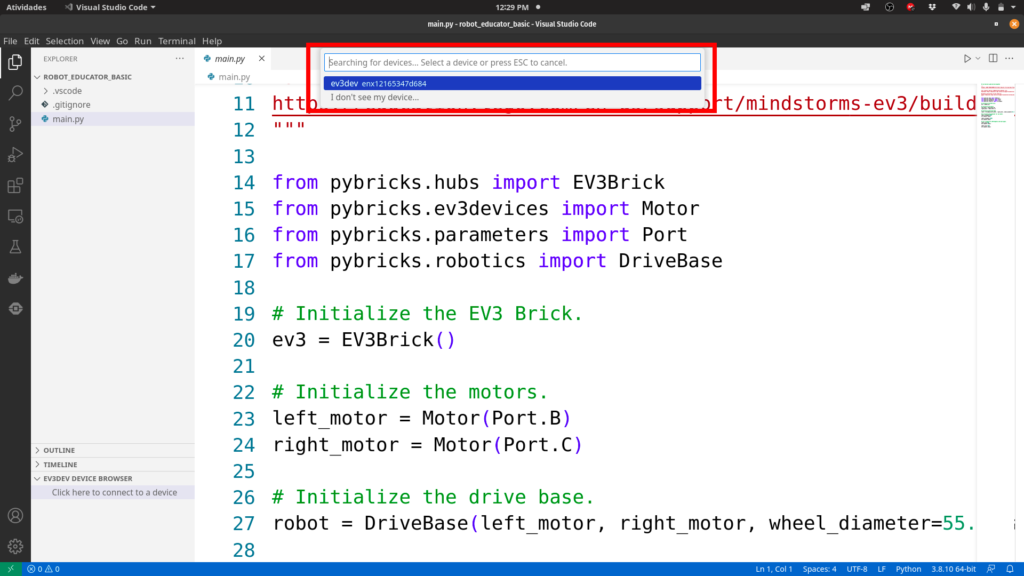
9º Depois do passo anterior (que não foi preciso no Windows) o dispositivo aparece com um ícone verde no menu lateral. O botão redondo, quando está com a cor verde, representa que o dispositivo está pronto para receber o seu código.

10º (Quase lá) Agora é preciso efetivamente passar o código para o EV3. Existe um ícone na extensão que parece com um ícone de download, e que ao passar o mouse mostra o texto “Send workspace to device”. Clicando no ícone o seu código será transferido para o Lego.

11º Se tudo deu certo uma mensagem “Download to ev3dev complete” vai aparecer na parte inferior direita da tela conforme a imagem abaixo.
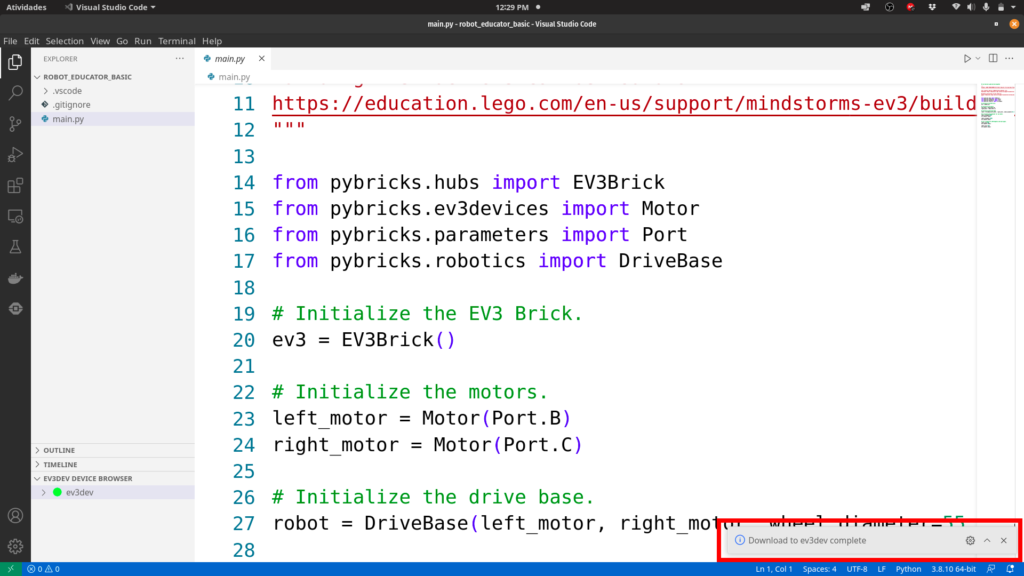
12º Por via das dúvidas antes de desconectar o cabo USB eu cliquei com o botão direito no dispositivo e cliquei em desconectar. Não diz no manual que isso é necessário mas achei bom garantir para prevenir que corrompimento dos dados.
13º Agora é só dar play no dispositivo e ver a “mágica” acontecer.
Desligando o robô
Se deu tudo certo talvez você fique em dúvida: “como eu desligo o Lego corretamente sem correr o risco de corromper o sistema de arquivos?”
Para fazer isso aperte o botão de “Voltar” e várias opções vão aparecer. Uma delas é desligar “Power Off” o robô. Selecione essa opção e aguarde alguns segundos até o computador desligar.




